Computación paralela
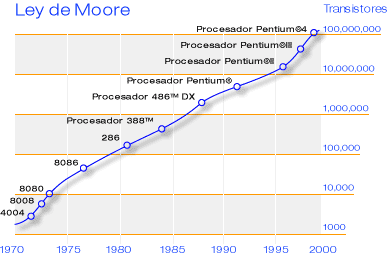
La ley de Moore
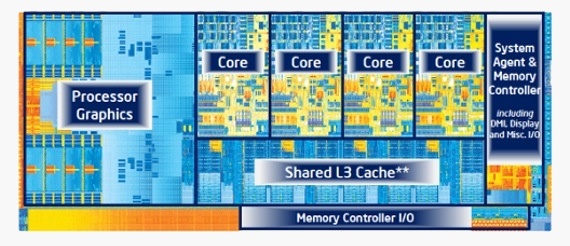
Procesadores con multiples núcleos (cores)

Clusters y supercomputadores
- En el cluster del IFA, Kosmos, hay $\sim 500$ cores disponibles.
- En supercomputadores modernos típicamente hay miles y miles de cores (Guacolda-Leftraru tiene 5236 CPU cores).
- TODO: Actualizar por EL CAPITAN -- El computador Fugaku (en Japón) es el más poderoso en el mundo por ahora, con más que 7,6 millones de cores. (Top500)


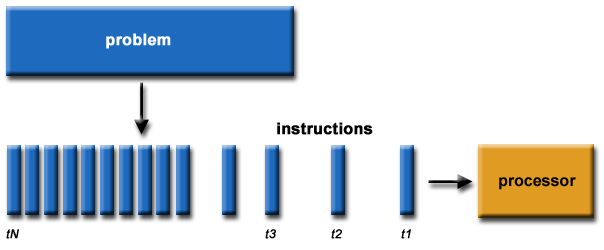
Programación Tradicional
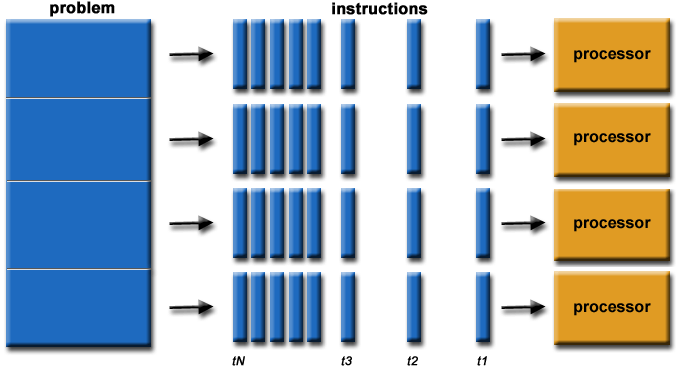
Programación en Paralelo
La jerga del paralelismo
Proceso: algo que se ejecuta en el sistema. Podría ser un navegador, un videojuego, un script de Python, etc.
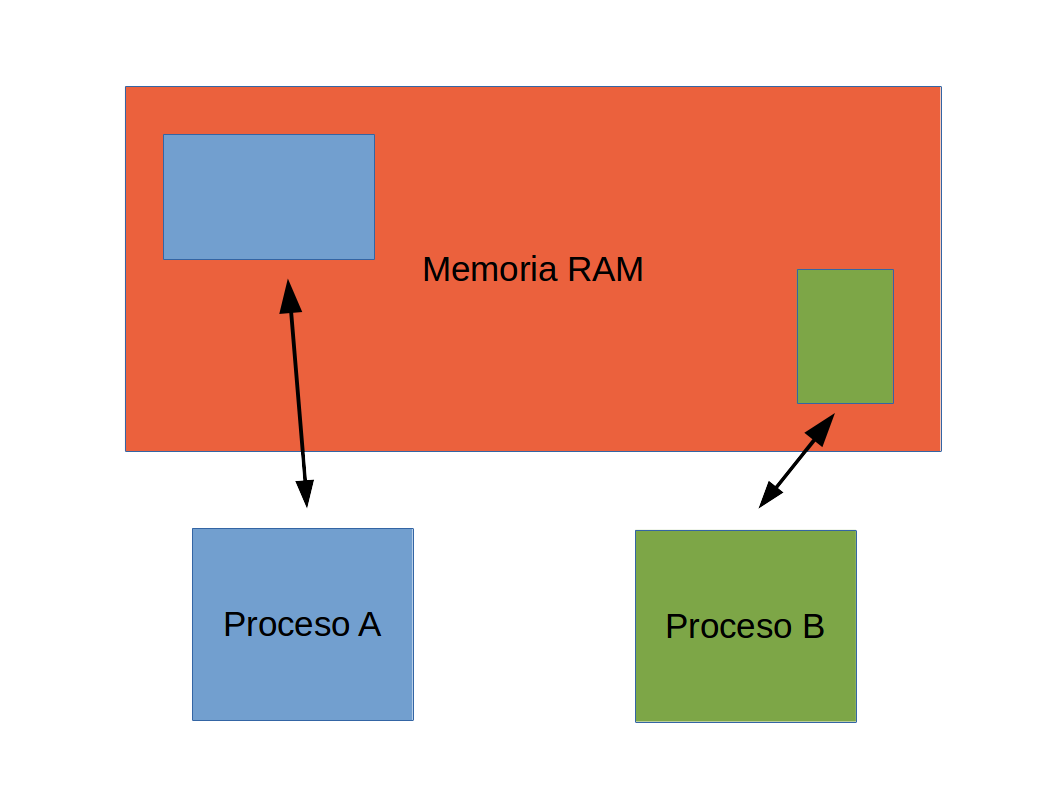
Memoria para procesos
- Cada proceso tiene acceso a la memoria que el sistema operativo le asigna.
- Típicamente, el bloque de memoria asignada al proceso pertenece exclusivamente a ese proceso.
- Otros procesos en el sistema no lo pueden acceder al mismo bloque de memoria.
La jerga del paralelismo
- Hilo (Thread): un subproceso comenzado por algún proceso controlador.
- Por ejemplo, un script de Python podría usar varios hilos durante su ejecución.
Tipos de paralelismo
- Multiproceso: se divide el problema en varios procesos que comunican entre si.
- Multihilo (multithread): hay un proceso, que puede usar varios threads (subprocesos) durante su ejecucion para trabajar en paralelo.
- Muchos algorítmos para procesamiento paralelo ocupan una mezcla de los dos tipos.
- Hay una relación entre el tipo de paralelismo y la arquitectura de la memoria...
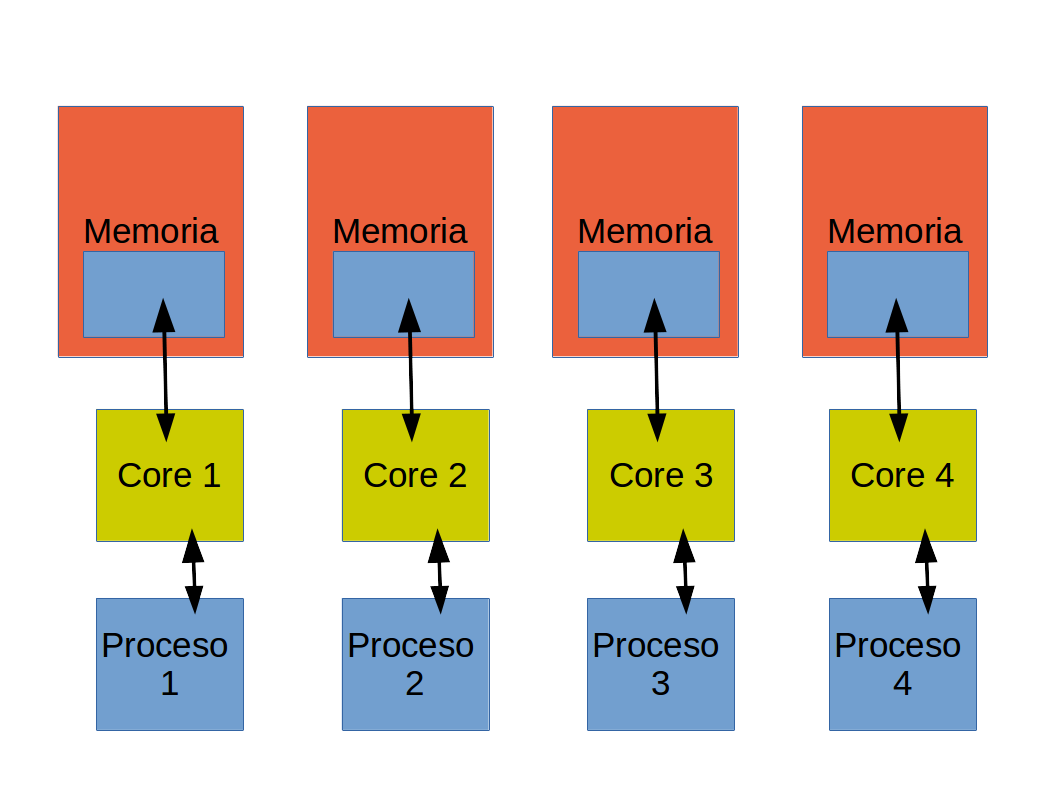
Paralelismo multi-proceso
- Hay múltiples "versiones" de un sólo programa (procesos múltiples).
- Cada proceso corre en uno de los núcleos (cores).
- Notar que cada proceso tiene su propio bloque de memoria. Esto se denomina memoria distribuida.
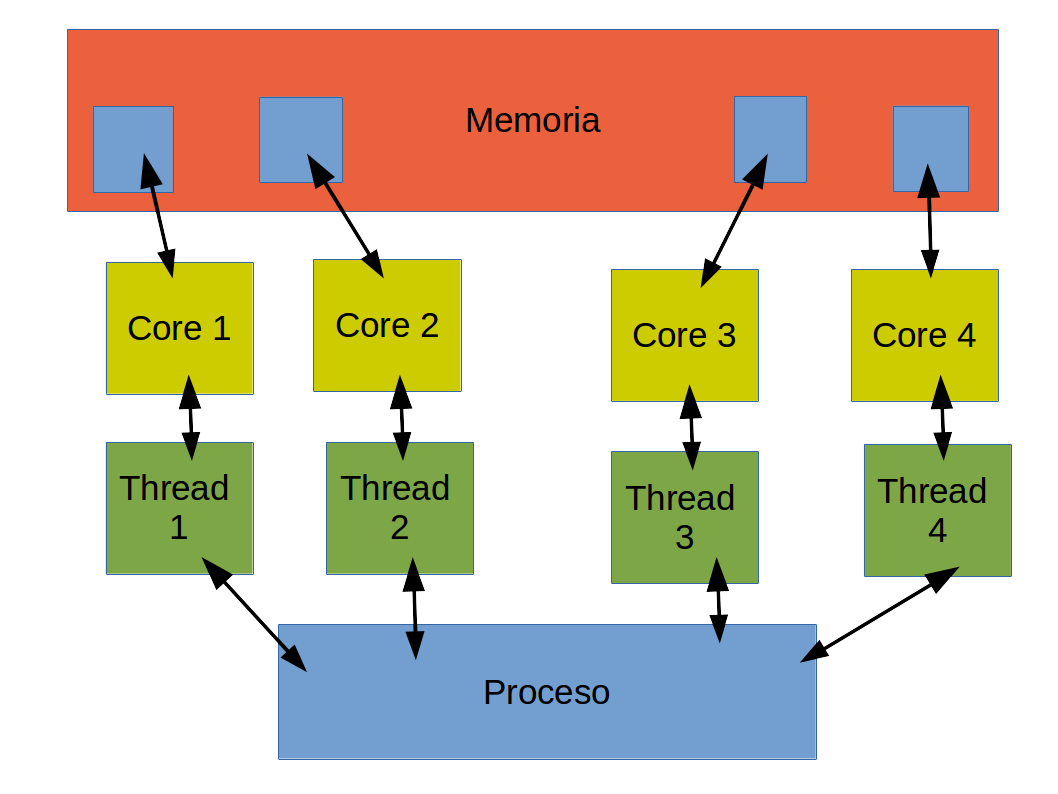
Paralelismo multithread (multi-hilo)
- Un proceso lanza multiples threads (hilos) de ejecución.
- Se generan subprocesos.
- Cada procesador (core) ejecuta un subconjunto de los hilos.
- En este caso, todos los hilos tienen acceso al bloque de memoria "global" del proceso principal, lo cual se denomina memoria compartida.
Ejemplo: paralelismo multiproceso
Ejemplo: paralelismo multiproceso en una simulación del clima.
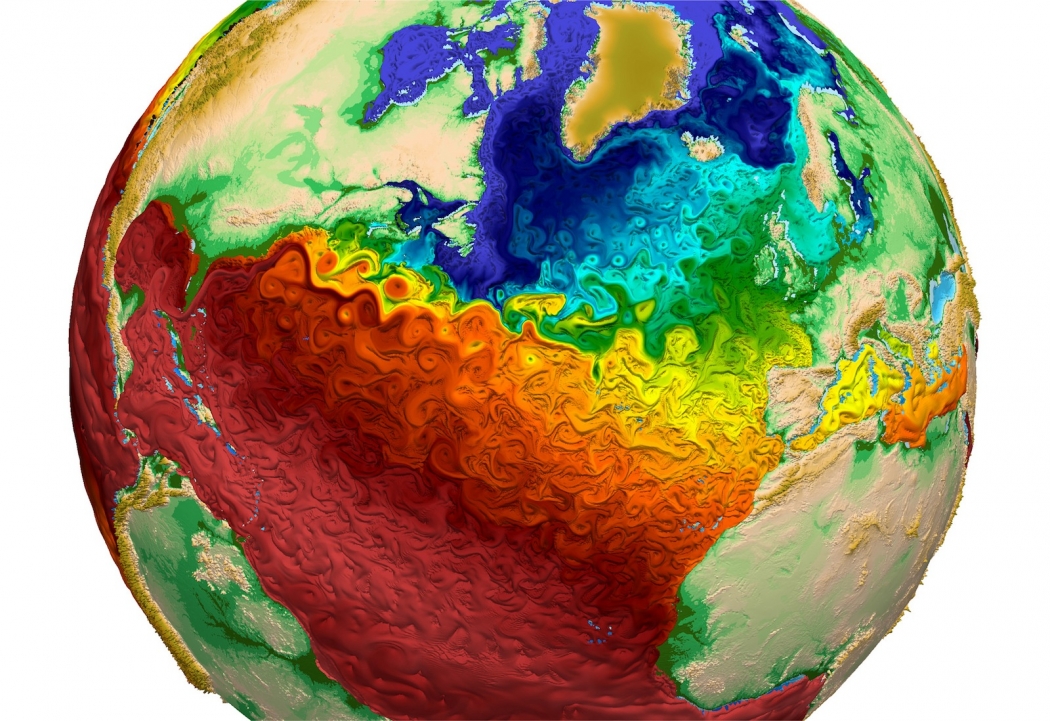
Simulaciones del clima
- En la simulación hay una malla esférica en $3D$.
- En cada elemento ("celda") de la malla, el programa calcula presión, densidad, temperatura, etc.
- Veremos más sobre simulaciones durante la próxima clase.
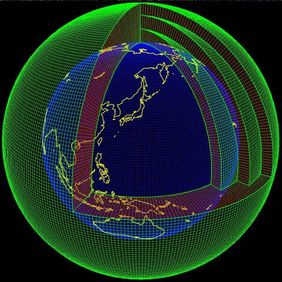
Simulaciones del clima
- Típicamente, la malla computacional tendrá $1.5$ millones de elementos (celda de área $100$ km$^2$, $30$ capas de la atmósfera).
- La simulación tiene que calcular el estado de la atmósfera en cada uno de estos puntos para $100$ años (de tiempo en la simulación), en intervalos de $30$ minutos.
$\Rightarrow$ $1.7$ millones de pasos en el tiempo...
$\Rightarrow$ $2.5 \times 10^{12}$ cálculos...
- Aún si cada cálculo demora $1$ microsegundo (optimista, dado la complejidad de las ecuaciones) la simulación demorará $\sim 30$ días corriendo en un procesador.
Simulaciones del clima
- Para acelerar la simulación, usamos paralelismo.
- En el caso de paralelismo multi-proceso:
- Ejecutamos varias copias del programa que hace la simulación.
- Cada copia se ocupa de solamente una parte de la malla total.
Simulaciones del clima
- Por ejemplo, si usamos $50$ procesos (cada uno a cargo de un core/núcleo), podemos:
- Dividir la malla en $30.000$ puntos por núcleo.
- Así que, cada núcleo hace una tarea menos exigente - hicimos una división del trabajo!
Pasos para correr la simulación en paralelo
- Se ejecuta el programa de la simulación: el primer proceso.
- Este proceso (número $1$) corre en uno de los núcleos y divide la malla en sub-mallas.
- Determinar cual división es la más eficiente puede llegara ser muy dificil: este es el primer gran desafio del paralelismo.
- Se lanzan otros $49$ procesos (cada uno en un núcleo diferente) para hacer los cálculos en su sub-malla asignada.
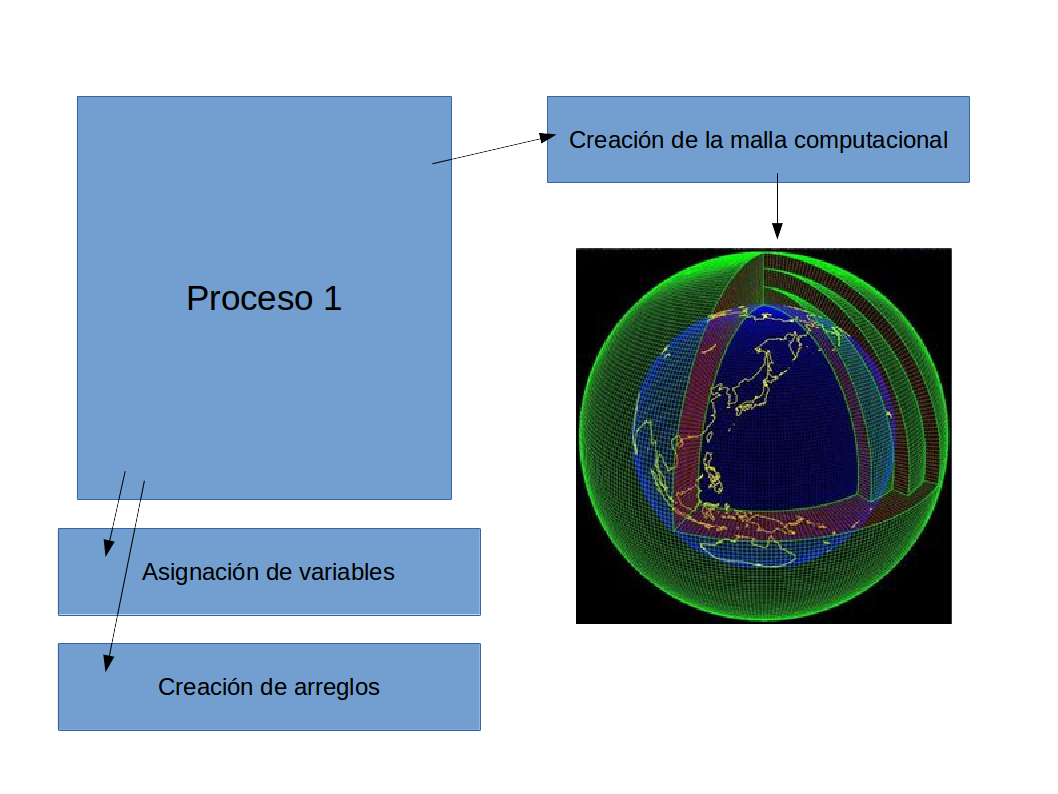
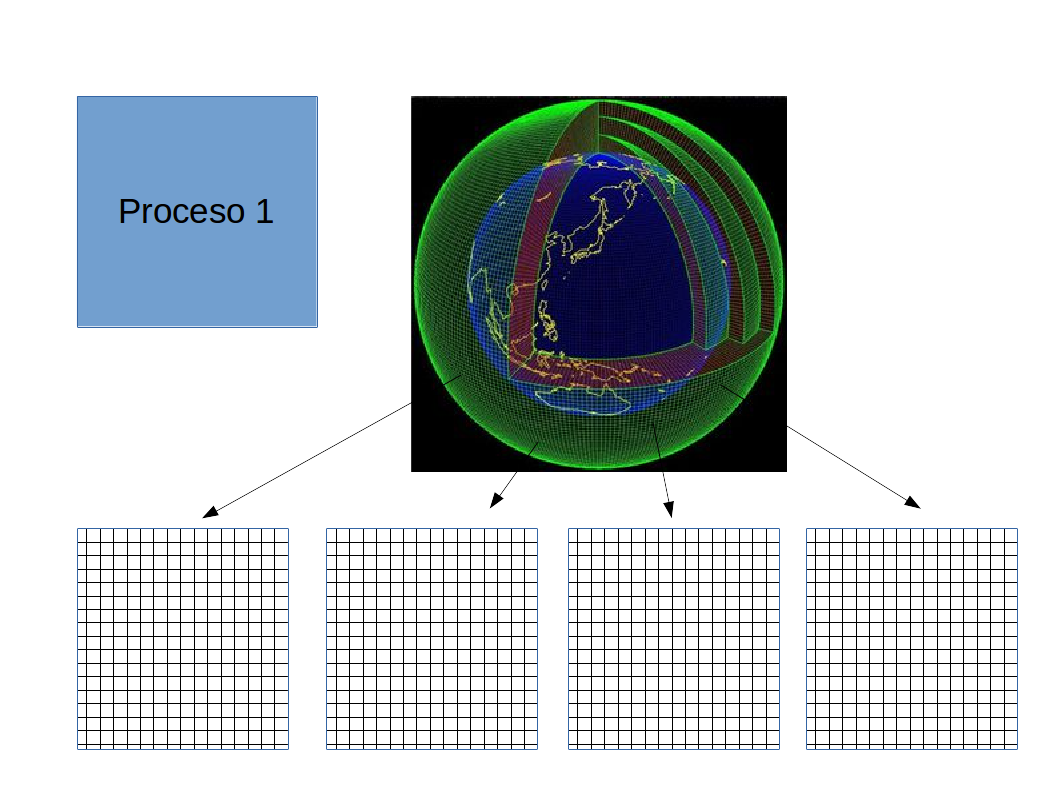
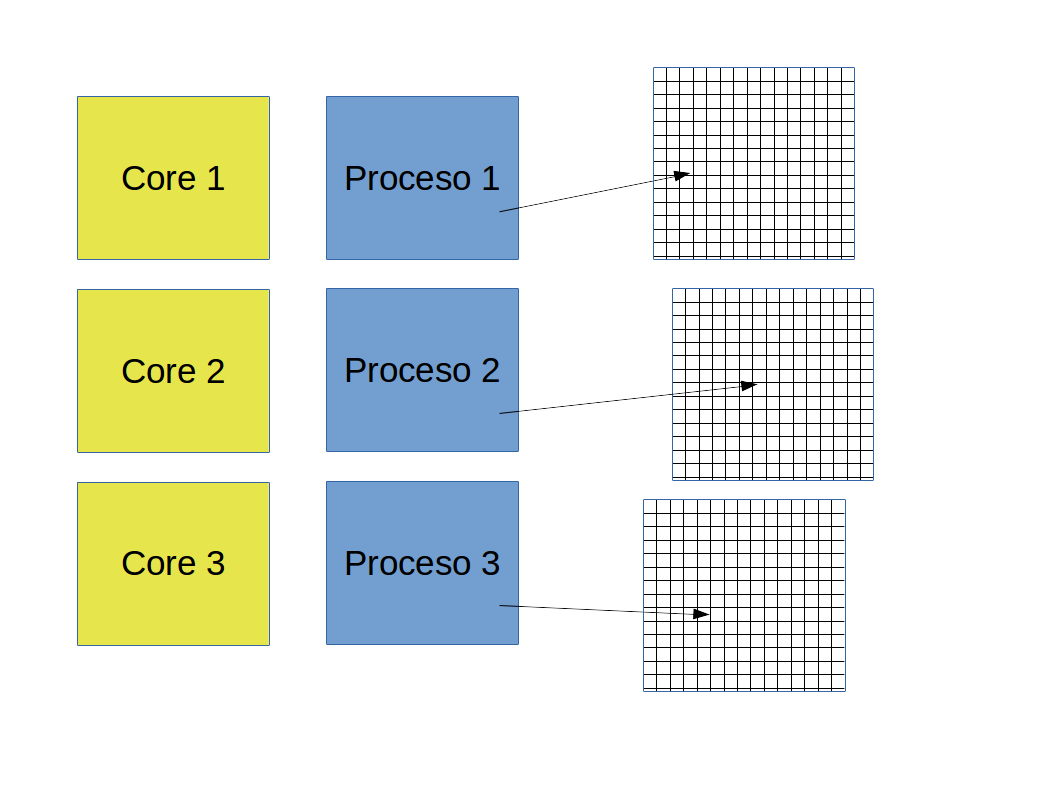
La ventaja de correr la simulación en paralelo
- Hemos dividido el trabajo entre $50$ procesadores.
- Si la división fue óptima, esperaríamos que la simulación debería correr $50$ veces más rápido.
- Entonces,
Comunicación
- ¡Ojo! Hemos olvidado algo MUY importante...
- Cada parte de la atmósfera está conectada con otras partes: no están aisladas y el aire se mueve!
- Luego, necesitamos comunicación entre los procesos para actualizar los valores en los bordes de las sub-mallas
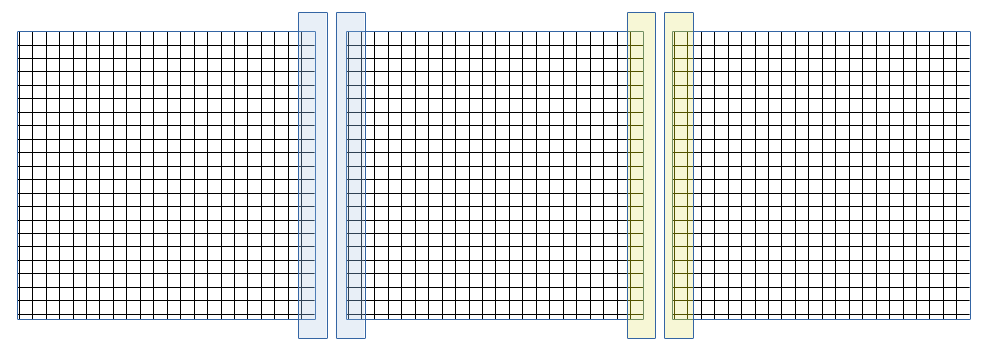
Comunicación
- Este es el segundo gran desafio del paralelismo: realizar de forma eficiente (y correcta) la comunicación entre los procesos/hilos.
- En este ejemplo, podemos escribir en el programa que cada proceso tiene que compartir los resultados en el borde de la sub-malla con todas las sub-mallas vecinas, en cada paso del tiempo.
- Típicamente se usan librerías específicas para el paralelismo (MPI, OpenMP, etc.)
Para terminar de correr la simulación en paralelo
- Los resultados de todos los núcleos se unen en en el proceso $1$ (usando comunicación entre los procesos).
- Luego, el proceso $1$ puede guardar los resultados en un archivo en el disco duro.
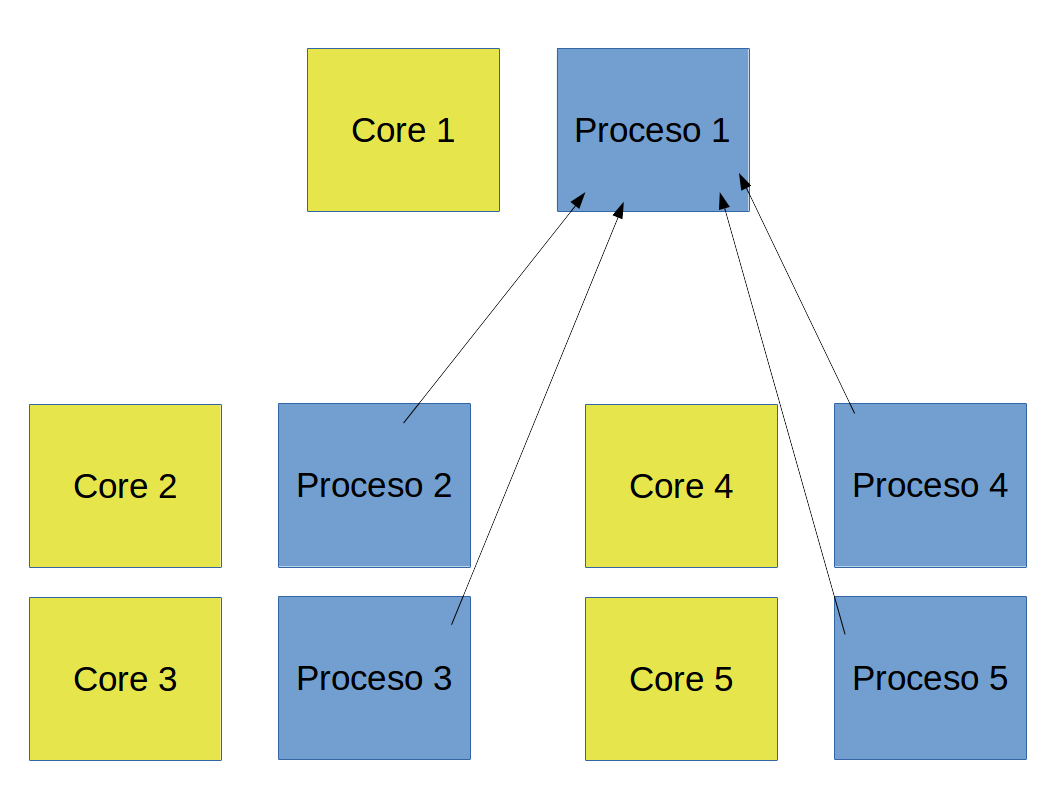
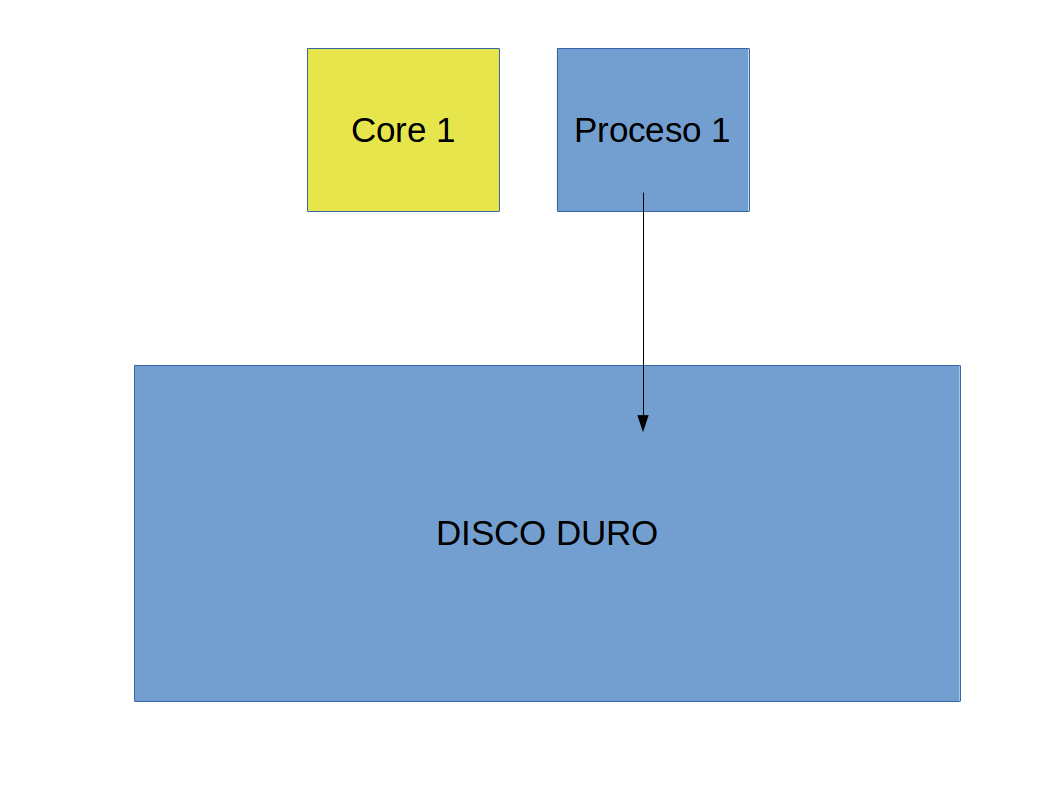
Resumen
- La rapidez de un core no está creciendo mucho actualmente, pero hoy en día los CPUs tienen muchos.
- Por lo tanto, hay que saber como diseñar algoritmos paralelos.
- Hay dos métodos principales: multi-proceso (memoria distribuida) y multi-hilo (memoria compartida).
- En el área de computación científica, la programación paralela es conocimiento esencial!